编译报告
在 GWT 中编程时,有时很难理解编译后的输出。对于 代码拆分 的用户来说尤其如此:为什么有些片段更大,有些更小?我们对这些问题的答案是编译报告。编译报告让 GWT 程序员能够洞察应用程序在编译期间发生了什么:代码导致了多少输出,哪些 Java 包和类导致了大量的 JavaScript 输出,以及代码在代码拆分期间如何拆分。有了这些信息,您就可以以目标化的方式修改应用程序,以减小整个编译应用程序的大小或某些片段的大小。
编译报告可以在常规的 GWT 编译期间生成。它包含一组 HTML 页面,这些页面可以轻松浏览和导航,并提供应用程序编译的图形表示。
目标
- 编译报告提供 GWT 应用程序编译的图形表示。
- 编译报告为程序员提供足够的信息来
- 能够减小代码大小。
- 能够减小特定片段的大小,特别是初始下载片段。
- 能够在排列之间进行比较。
- 信息以一组易于导航的静态 HTML 页面显示。
- 编译报告是可选的,并且可以方便地在编译期间通过简单地设置一个 GWT 编译器标志来创建。
用法
默认情况下不会生成编译报告,但可以通过设置编译器标志轻松让编译器生成报告。当设置标志时,GWT 编译器会在编译期间收集必要的信息,并以 HTML 文件的形式生成编译报告。以下编译器标志可用
- -compileReport: 生成标准编译报告(如本文档中所述)。默认情况下,报告将写入名为 extras/[moduleName]/soycReport/compile-report/ 的目录中。您可以使用 -extra 编译器标志更改输出目录。
- -XsoycDetailed: 生成标准编译报告以及所谓的“stories.xml”文件,这些文件详细说明了特定 Java 代码片段和 JavaScript 代码片段之间的连接。stories 文件在调查特定 JavaScript 代码片段时最为有用。
用户通常希望从文件 compile-report/index.html 开始浏览编译报告。默认情况下,此文件将位于 compile-report 目录中,除非包含 -extra 编译器标志。
功能
所有排列的概述
用户将看到的第一个屏幕是特定编译报告包含的所有排列的概述。下图 1 显示了此概述屏幕。您可以看到它列出了每个排列的属性,例如用户代理、语言环境等。
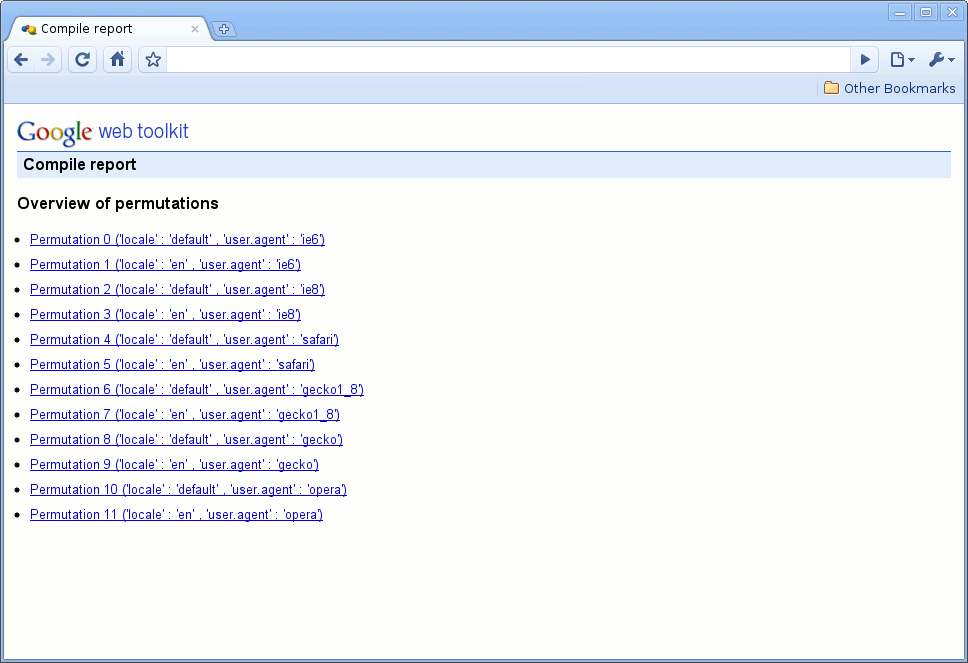 图 1: 所有排列的概述
图 1: 所有排列的概述
总体大小
在编译报告中要查看的第一件事是应用程序的总体大小细分。
图 2 显示了一个排列的概述。在顶部,您可以看到完整的代码大小、初始下载大小以及剩余的代码。初始下载大小是在加载应用程序时下载的代码量。如果未使用代码拆分,它将与完整的代码大小相同,否则通常会小很多。有关剩余代码的更多信息,请参阅 代码拆分 文档。位于大小正下方的链接将引导您了解这些大小的更详细信息。
在此信息下方,编译报告列出了代码拆分生成的单个代码片段的大小。
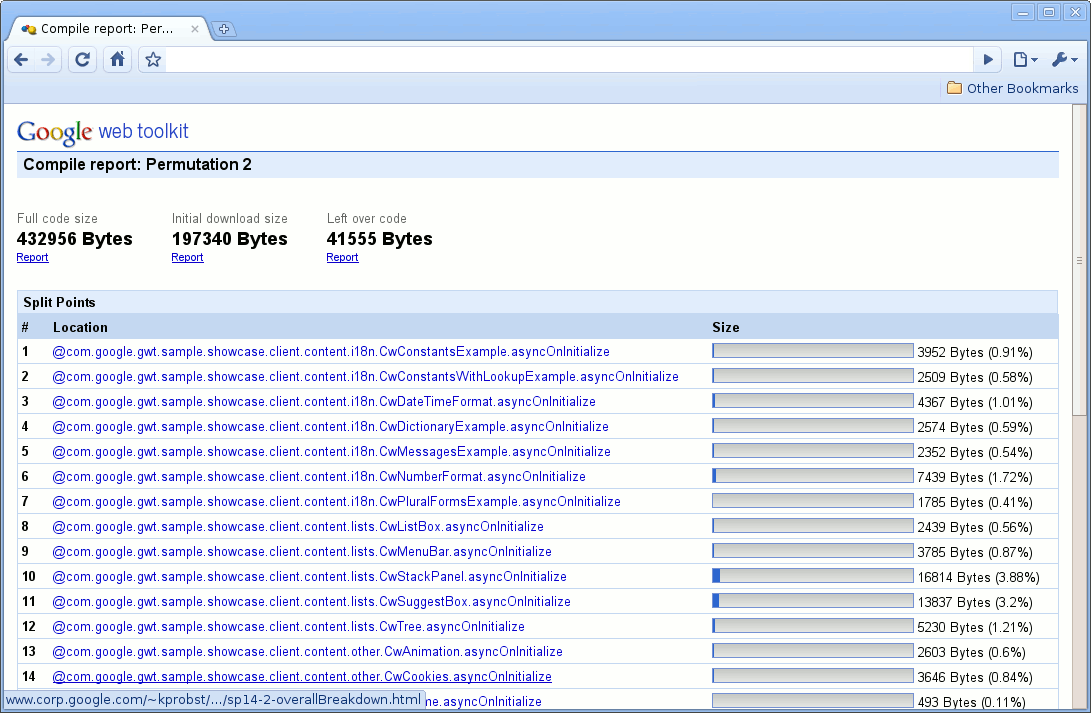 图 2: 一个排列的概述
图 2: 一个排列的概述
包和代码类型细分
在分析了整个应用程序的大小以及特定代码片段的大小之后,用户可以深入了解这些大小的细节。图 3 显示了编译报告提供的细分。应用程序首先按包进行细分。本节列出了应用程序中的所有包,以及它们生成的 JavaScript 代码量。
编译报告还按代码类型提供细分
- JRE 指的是 JRE 代码(例如,java.util.HashSet)
- gwtLang 指的是 GWT 语言代码,例如由代码拆分生成的代码(com.google.gwt.lan.asyncloaders.AsyncLoader37)。
- allOther 指的是用户代码或可以纯粹归因于您的应用程序的代码(例如,com.google.gwt.user.client.ui.Grid 或 com.google.gwt.sample.client.Showcase,正在分析的应用程序)。最后,报告还列出了字符串占用的空间。
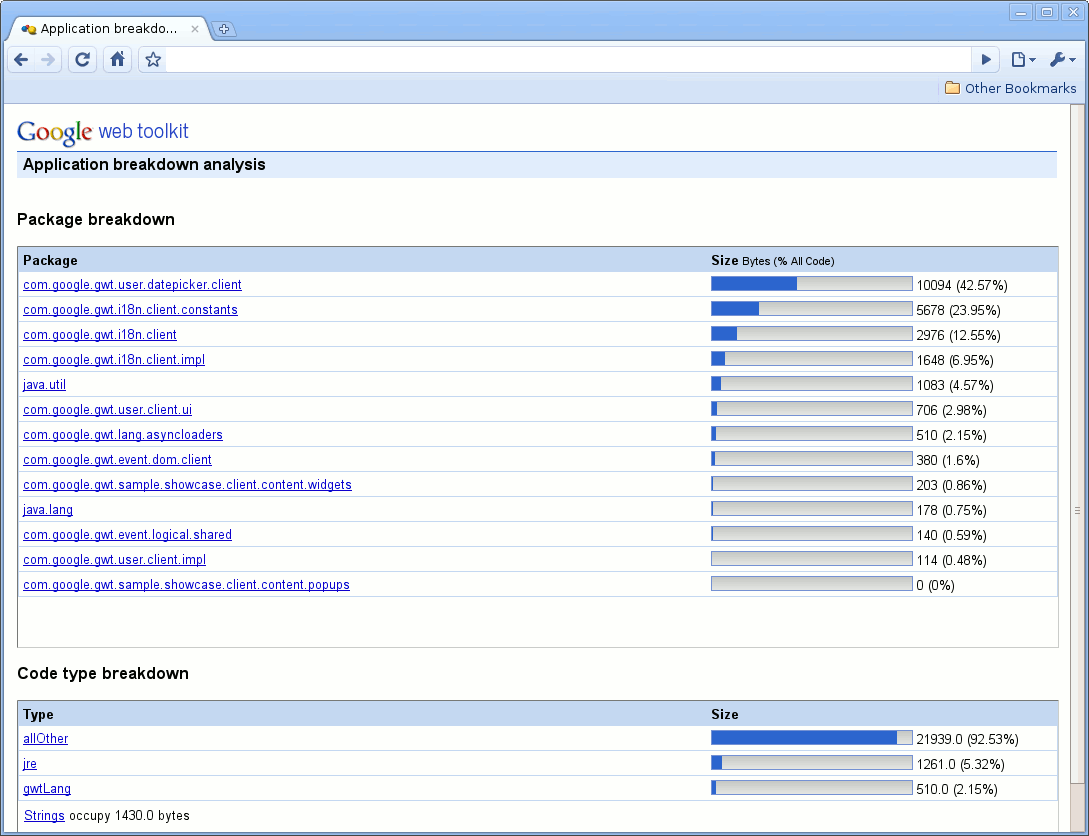 图 3: 包细分
图 3: 包细分
此概述细分特别有用,例如,可以了解 JRE 代码导致了多少代码大小。例如,如果您发现对 java.util.HashSet 的使用导致您的应用程序变得过大,您可能会找到一种方法来避免在代码中使用 java.util.HashSet。
依赖项
在某些时候,您会尝试将某些东西移出初始下载片段,但 GWT 编译器会将其放在那里。有时您可以很快弄清楚原因,但有时根本不明显。查找方法是查看编译报告中报告的依赖项。最常见的示例是,您希望某个项目(例如,一个类)从初始下载中排除,但它没有被排除。要找出原因,请通过“初始下载”代码子集浏览到该类(从概述中,单击相关的排列,然后单击“初始下载大小”下方的“报告”链接。然后单击该类的包)。单击该类后,您可以查看一连串依赖项,这些依赖项回溯到应用程序的主入口点。这是 GWT 认为该项目必须在初始下载中的依赖项链。尝试重新排列代码以打破该链中的一个链接。
另一个不太常见的示例是,您希望某个项目专属于某个拆分点,但实际上它只包含在剩余片段中。在这种情况下,请通过“总程序”代码子集浏览到该项目。然后,您将看到一个页面,描述该项目的代码最终出现在哪里。如果该项目不专属于任何拆分点,那么您将看到所有拆分点的列表。如果您单击其中任何一个,您将看到该项目的依赖项链,其中不包含您选择的拆分点。要使该项目专属于某个拆分点,请选择一个拆分点,单击它,然后打破出现的依赖项链中的一个链接。
图 4 显示了一个类的调用堆栈示例。它显示了如何将它的方法追溯到一个入口方法,在本例中是 onModuleLoad(GWT 模块的标准入口方法)。
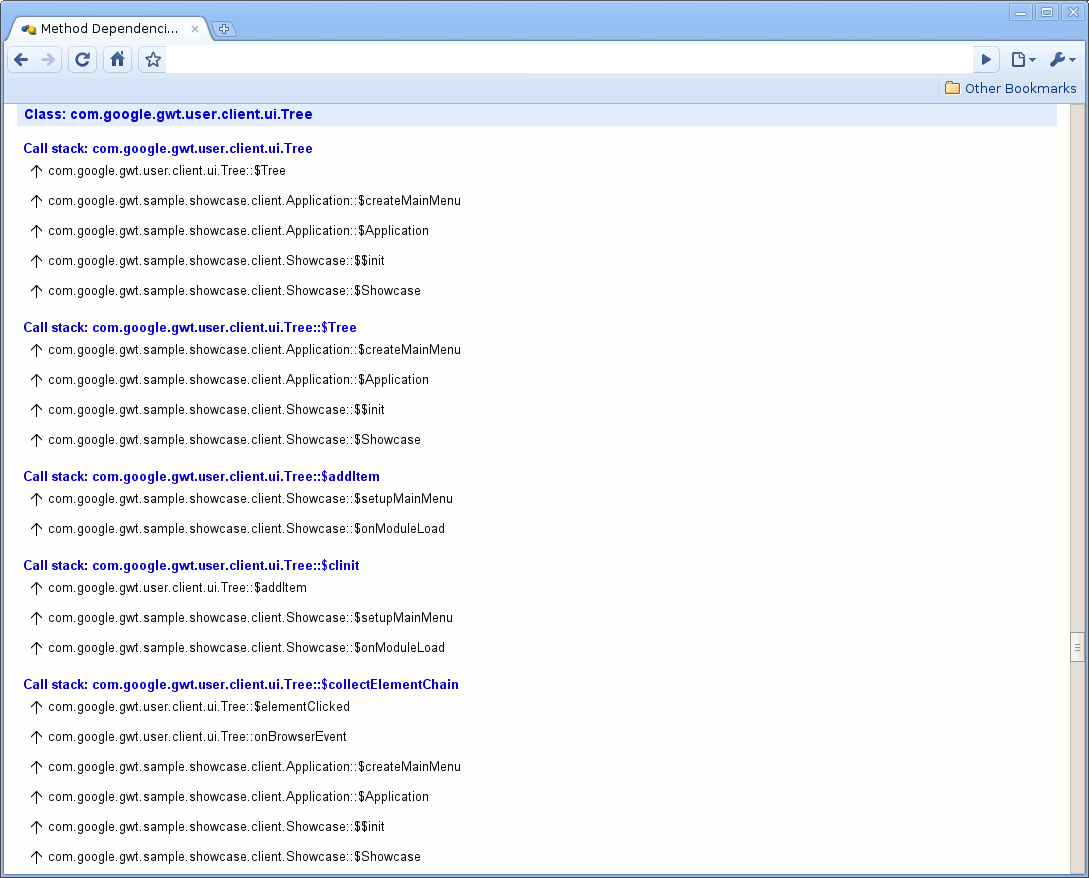 图 4: 方法依赖项
图 4: 方法依赖项
拆分点状态
如上所述,编译报告通常与代码拆分一起使用。编译报告帮助回答的问题之一是编译后的特定类的代码最终包含在哪个片段(或片段)中。当向下钻取到总程序的特定类时,分析此类的编译后的代码最终出现在哪里通常很有用。它将出现在初始片段中、特定拆分点片段中还是剩余片段中?它会在不同的片段之间拆分吗?拆分点状态页面旨在回答这些问题。下图 5 给出了这样一个页面的示例。它说明了该类的部分代码最终出现在剩余片段中,并解释了原因以及为什么它没有出现在另一个片段中。例如,单击链接“查看为什么它不专属于 s.p. #7”将引导您进入一个调用堆栈,解释了为什么该代码不专属于拆分点 7,而是也需要用于另一个拆分点。反过来,这也解释了为什么该代码位于剩余片段中。有关专有片段和剩余片段的更多详细信息,请参阅 代码拆分 的文档。
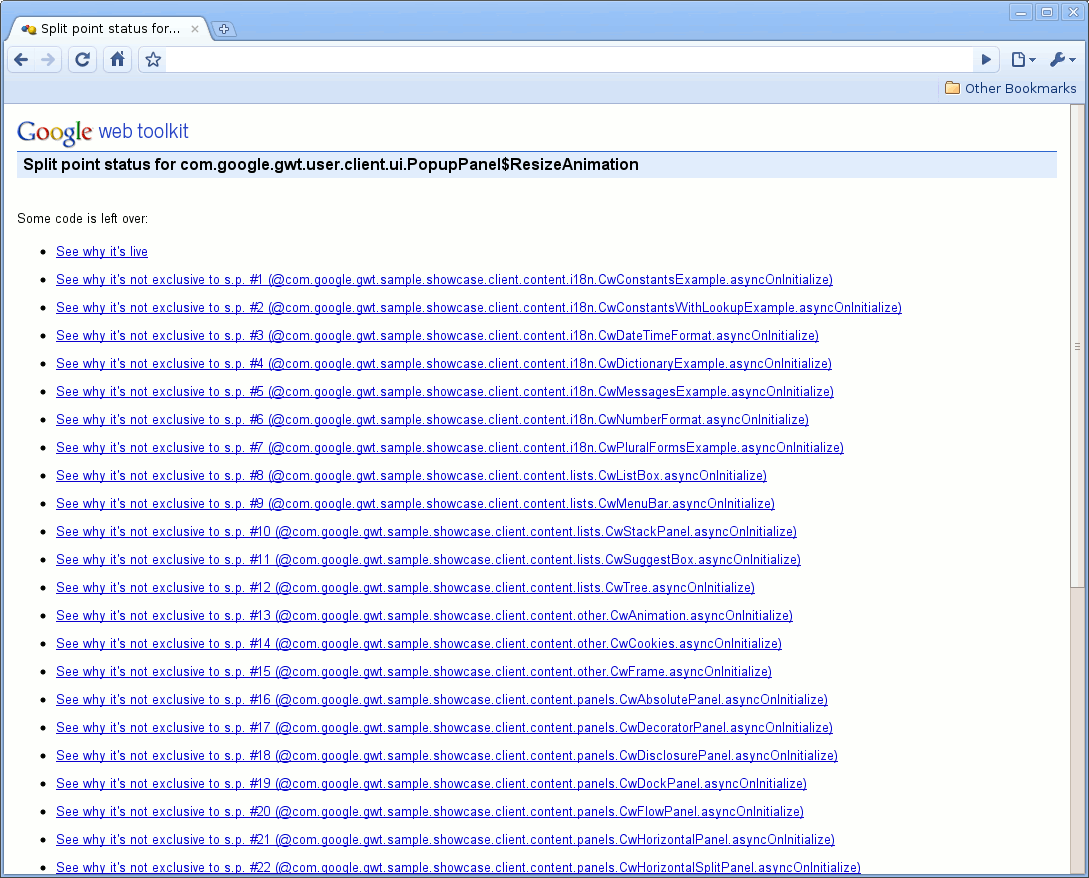 图 5: 拆分点状态
图 5: 拆分点状态
用例
编译报告有四个主要的用例
- 为了减少下载大小
- 为了减少初始片段的下载大小
- 为了减少代码分割产生的特定代码片段的下载大小
- 为了比较不同排列组合,例如,用户代理之间的差异
在最初的三个用例中,编译报告可以用来找出哪些代码进入哪些片段,以及哪些包或类对下载大小的“责任”最大,即哪些包或类对编译后的代码贡献最大。程序员应该如何使用编译报告来减小应用程序的大小?有两种基本方法
完全消除某些类或包
让我们以一个初始下载代码片段为例,换句话说,启动应用程序所需的代码。当不使用代码分割时,初始下载大小将是整个程序,但当使用代码分割时,它可能会小得多。在这种情况下,程序员会想知道程序的哪些部分最初被下载。例如,图 6 显示了在我们的示例应用程序中,所有在 java.lang 包中对初始下载有贡献的类。程序员可能会看到这一点,并决定取消使用 java.util.AbstractHashMap,这将反过来减少此应用程序的初始下载。这种策略可以多次执行:针对那些对初始下载贡献最大的类,并将其删除。例如,程序员可以选择使用更少的组件、更少的 Java 语言包/类等。
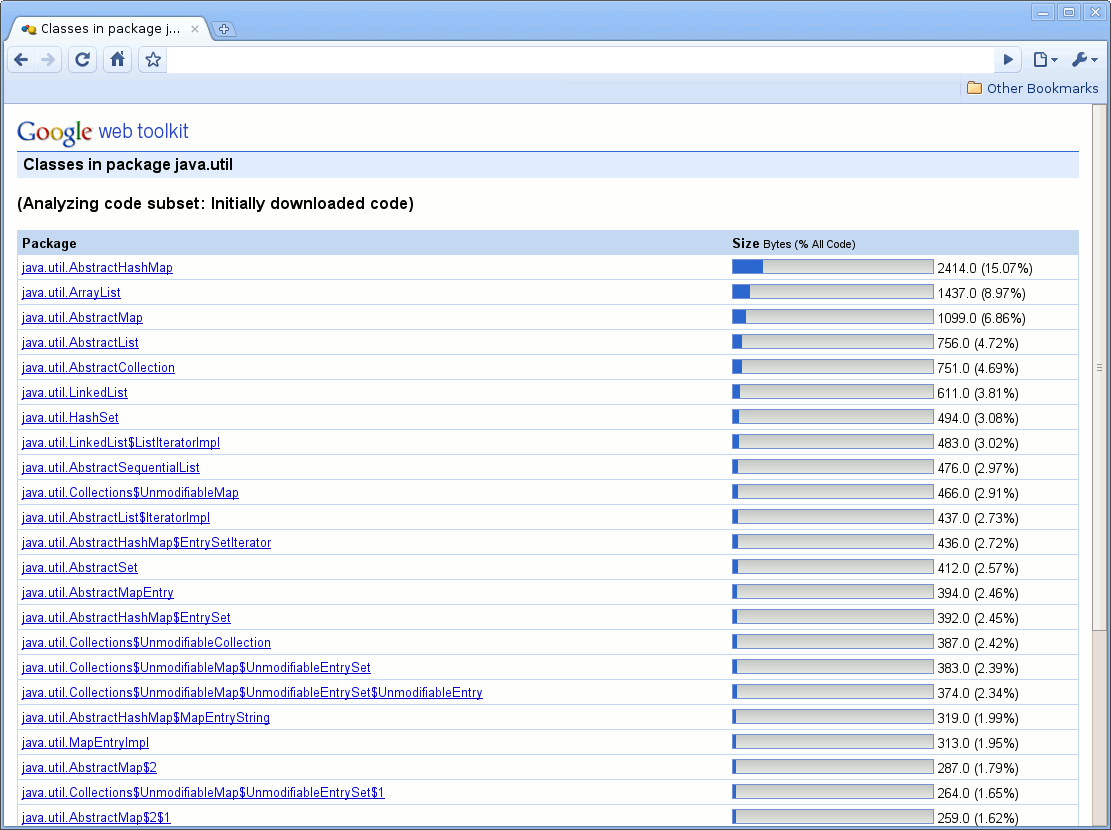 图 6:初始下载中 java.util 用例示例
图 6:初始下载中 java.util 用例示例
设置分割点,以消除其他片段中的某些代码,例如从初始下载中消除
特别是在初始下载大小的背景下,考虑一些对于程序启动来说并非严格必要的功能(比如“设置”选项卡)。为了从初始片段中删除这段代码,程序员可以选择在该功能周围设置一个分割点,这样它的代码只会在需要时才被下载,从而从初始片段中删除。编译报告可能会清楚地表明,此功能会向初始片段添加大量代码,因此值得从初始下载中删除。